
喜田研究室のYoutubeはこちらをクリック

授業や実験・演習を公開しています!
研究テーマ紹介
1. 画像データが面白い
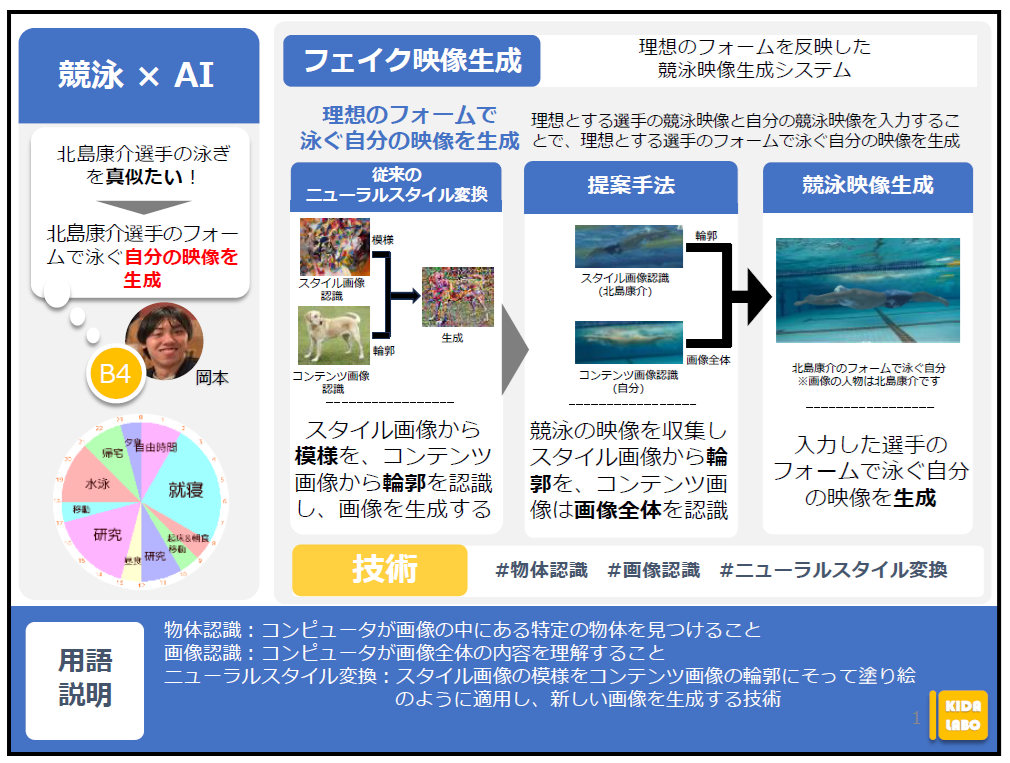
理想のフォームを反映した 競泳映像生成システム
◯研究テーマ
私の研究では、理想のフォームを反映した競泳映像生成システムの開発を行っています
◯背景
皆さんはトップ選手の真似をしたことはありませんか?僕は競泳をしているのですが、トップ選手、特に北島康介選手の泳ぎを真似したいと思っています。
しかし、北島康介選手の映像だけだと把握しづらく、真似しにくいと思います。
その為、トップ選手のフォームで泳ぐ自分の映像が生成するシステムを開発することで把握しやすくなり、真似がしやすくなると考えました。
◯研究内容
私の研究ではニューラルスタイル変換という技術を改良して実現を目指します。
ニューラルスタイル変換はスタイル画像から模様を、コンテンツ画像から輪郭を認識し、輪郭に沿って塗り絵のように模様を適用して新しい画像を生成する技術です。
この技術は模様を変えることはできるのですが、形だけを変えることはできません。
そのためコンテンツ画像の形だけが変わることを目指します。
まず、コンピュータが水中映像における人物を認識できるように競泳の水中映像を集めます。
その後、スタイル画像から輪郭を、コンテンツ画像から画像全体を認識します。
生成する画像と認識した情報と比べていき、自分の体や背景は保持されたまま形が変わった画像を生成します。
このようにしてできた画像をあわせて、理想とする選手のフォームで泳ぐ自分の映像が生成できると考えています。
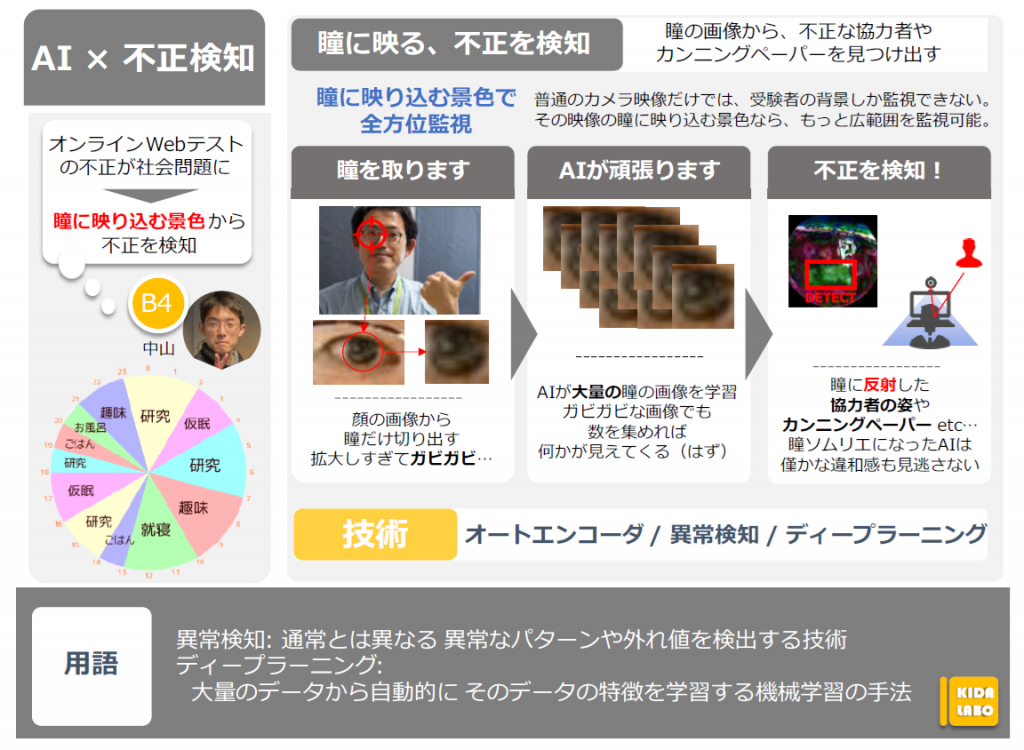
瞳の画像から、不正な協力者や カンニングペーパーを見つけ出す
〇 研究テーマ
オートエンコーダーを用いた瞳画像の分析による、不正検知システムの開発
〇 背景
近年、パソコンを使用してオンライン上で受けるテスト(いわゆるWebテスト)が、学校や就職活動などで活用されると同時に、受験者の行う不正が問題視されています。
私のシステムでは、瞳に反射する周囲の風景を分析し、通常のカメラの画角では検出できないような場所にいる不正の協力者や、カンニングペーパーの存在を検出することを目指しています。
〇 研究詳細
瞳に反射する風景は鏡などよりも不明瞭かつ非常に小さいため、カメラで撮影すると大量のノイズが混じってしまいます。
そこで私の研究では、オートエンコーダーという、工場のレーンで不良品検知などに使用されるAI技術を使用しています。
このAIには何が何が正解で何が不正解かを教え込む必要がありません。
このような、自身で正解と不正解を区別してくれる取り扱いやすさが特徴になっています。
AIにノイズも含めて学習させ、AI自身に正常な風景+ノイズを理解させることで、ノイズに邪魔されることなく異常物の検知が行えると考えています。
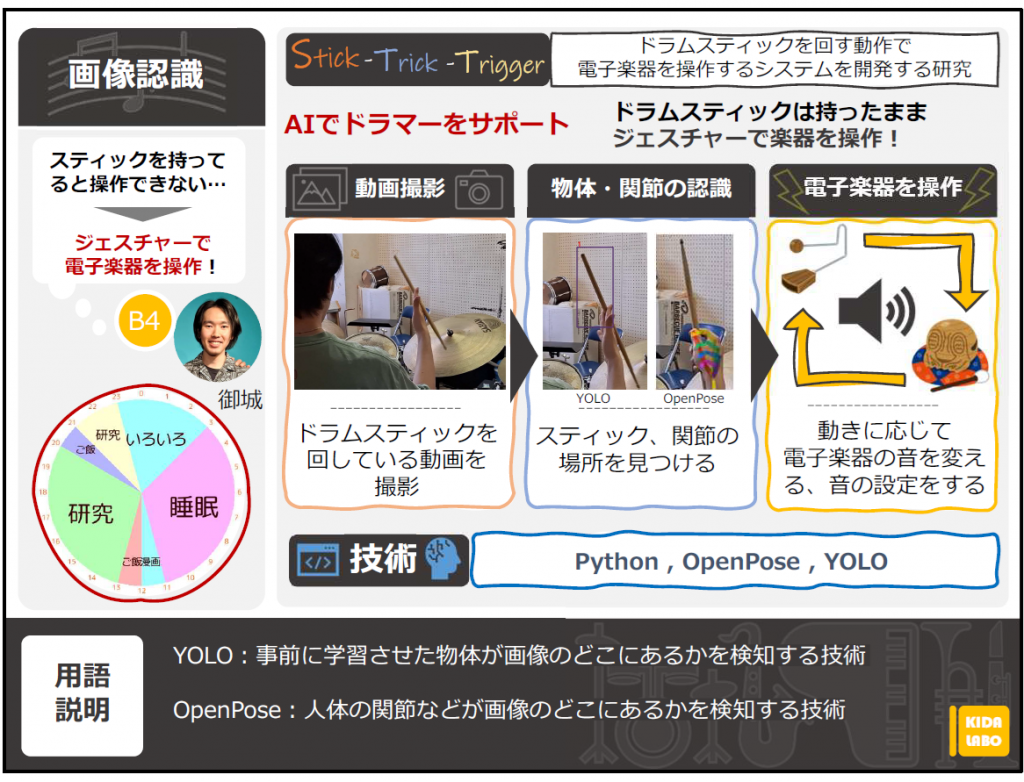
ドラムスティックを回す動作で 電子楽器を操作するシステムを開発する研究
ドラムセットを演奏するとき、両手にはドラムスティックを持っています。
その状態から電子楽器などを操作するためには、ドラムスティックを手から放す必要があります。
私の研究は、このひと手間を省くためのシステムを作ることです。
このシステムでは、ドラムスティックを回す動作、いわゆるスティック回しの動作をAIで見分けて、その動作に応じて電子楽器を操作します。
利用する技術は、物体検知、姿勢推定といった技術です。
物体検知では、事前に機械に学習させた物体が画像の中でどの位置に映っているかを調べることができ、姿勢推定では、画像に映った人体の関節がどこにあるかを調べることができます。
本研究では、これらの技術で得られる情報(画像の中で何がどこに映っているか)を分析し、どのような動作が行われたかを機械学習を用いてリアルタイムで見分けられるようにします。
この見分けた結果に応じて、電子楽器を操作します。
2. センサーデータが面白い
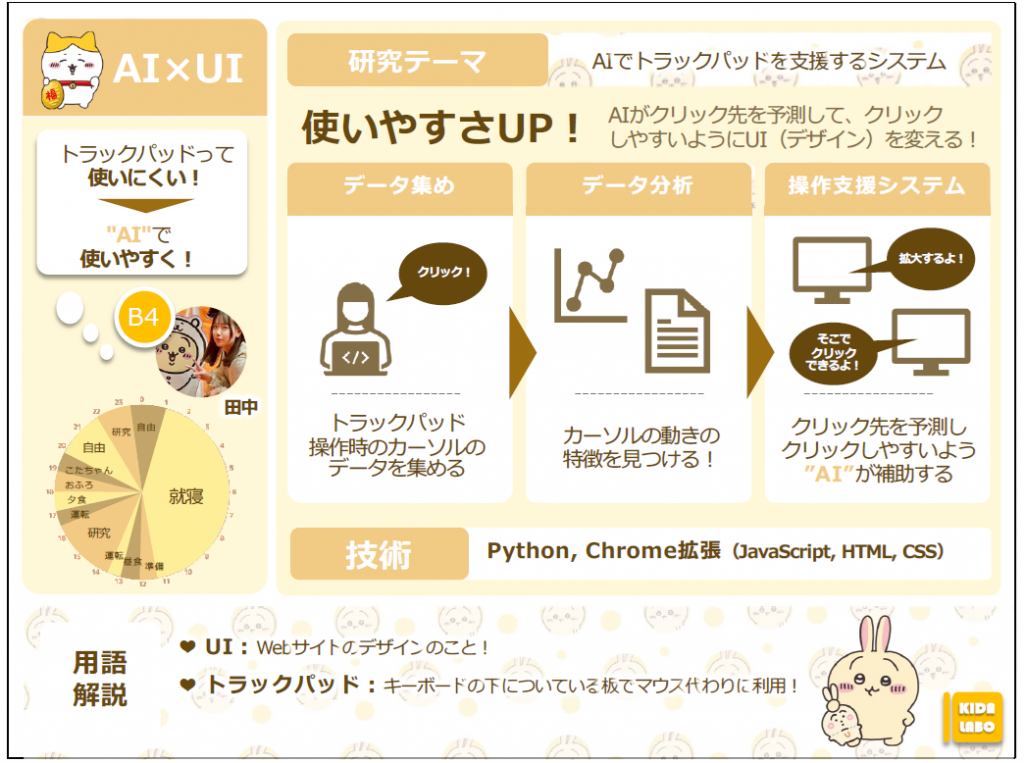
AIでトラックパッドを支援するシステム
❤ 研究テーマ
私の研究ではトラックパッドを使いやすくするためのシステムを開発しています。
このシステムではAIを使っています。
❤ 開発システム
トラックパッド操作時にどこをクリックしようとしているのかを予測するAIと、そのAIの予測結果から⾃動でUI(サイトのデザイン)を拡⼤させるシステムや、クリックしたいところに⾏かなくてもその場でクリックできるようなシステムを開発しています。
これからは予測するAIの精度を上げたり、使いやすいUIを開発したりして、さらにトラックパッドを使いやすくしていきます。

スマートフォンのセンサを活用して AIで認証システムを作る研究
はじめに
私は、スマートフォンのセンサを活用してAIで認証システムを作る研究をしています。
2要素で認証する2段階認証で、2回入力するのめんどくないですか?(要素1:パスワード、要素2:ワンタイムパスワードなど)
私の研究では、1回入力するだけで、2要素を取得して多要素認証できるようにする研究しています。(要素1:パスワード、要素2:入力時の本人の癖)
利用イメージ
・パスワード登録時:パスワードを10回入力します。
ここでユーザ専用のAIを作るためのデータを収集しています。
そのユーザ本人のデータとあらかじめシステム内に保存している他人のデータを用いて、ユーザ本人か他人かを判定するAIを作ります。
・認証時:パスワード1回入力するだけで、AIが「本人か他人か」を判定します。
システムの流れ
データ収集
スマホのセンサデータ(タッチ座標、角速度、加速度、指圧)を取得します。
データ分析
取得したセンサデータを分析し、ユーザ本人の癖を見つけてユーザ専用のAIを作ります。
認証システム
パスワードを入力するとAIが本人かどうかを判定します。
現在取り組んでいる課題
普段、スマホを使うときの持ち方は毎回同じではないことが多いと思います。
例えば、両手で持って両方の親指で操作したり、左手に持って右手の人差し指で操作したりと、同じ人でもその時々で持ち方が異なると思います。
そのため、パスワードを登録する時と認証する時のスマホの持ち方が異なると、センサデータが大きく変わり、同じ人であっても認証に失敗することがあります。
そこで、私はパスワードを登録する時と認証するときでスマホの持ち方が異なっても、認証できるように研究を進めています。
様々な持ち方でパスワードを入力した時のセンサデータを収集し、そのセンサデータをもとに、登録時と認証時の持ち方が違っても認証できるアルゴリズムの開発に取り組んでいます。
3. ログデータが面白い

ログを画像にしてシステムの異常検知をする研究
◾研究テーマ
画像化したログを⽤いてシステムの異常検知を⾏う研究です。
◾背景
近年、サイバー攻撃が巧妙化し、被害が拡⼤しています。
被害を最⼩限に抑えるためには、兆候の段階で攻撃に気づくことが重要ですが、攻撃の兆候となる異常なログの数が少ないです。
そのため、データと正解を⼀緒に学習させる教師あり学習の異常検知で⾼い精度を出すことは難しいです。
また、従来の機械学習やルールベースによる異常検知では、誤検知が多いことも課題となっています。
◾研究の詳細
平常時のログを学習させておくことで、平常とは異なる状態、つまり異常を検知するシステムを開発しています。
データのみを学習させ、パターンや関係性を⾒つける教師なし学習の画像の異常検知で、オートエンコーダという技術があります。
システムログ全体を画像化し、その画像をオートエンコーダを⽤いて異常検知することで、システムの異常に気づくことができるのかを検証します。
また、⽂字ではなく画像を異常検知することで、誤検知の少ない異常検知⽅式を⽬指します。
オートエンコーダ補足説明
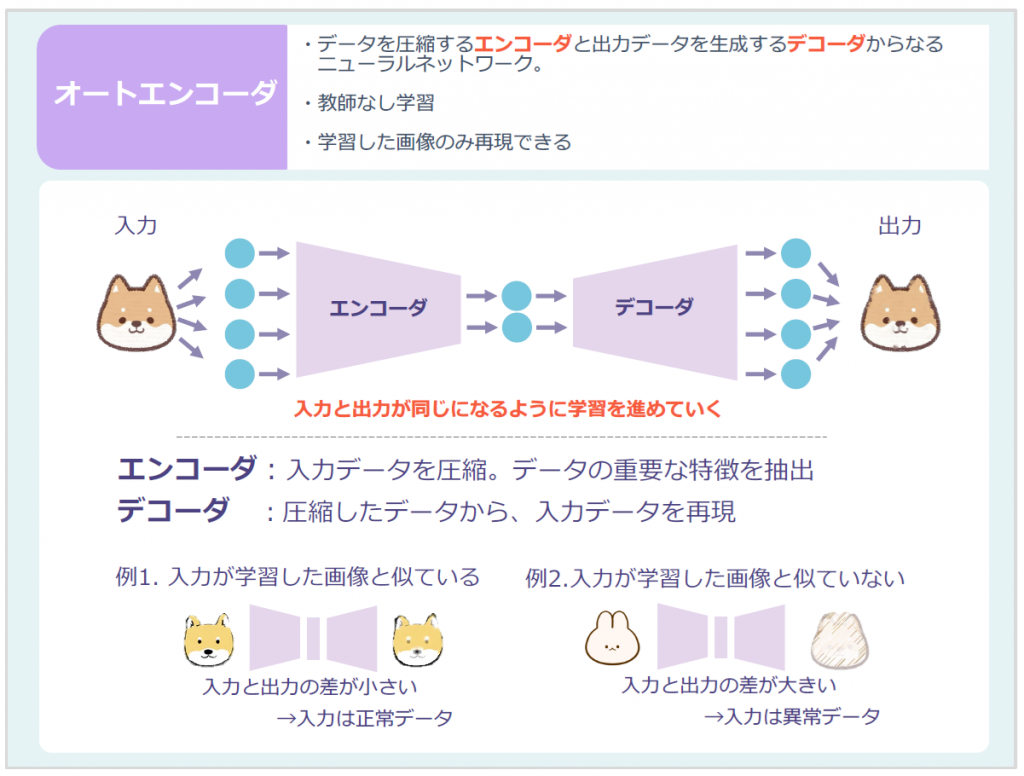
オートエンコーダは、データを圧縮するエンコーダと出⼒データを⽣成するデコーダからなるニューラルネットワークです。
エンコーダでは、⼊⼒画像のうち重要な特徴のみを抽出します。
デコーダでは、エンコーダで抽出した特徴から、⼊⼒画像に近づけるように画像を復元(再構成)します。
これにより、学習した画像のみを再構成することができます。
学習した画像と似た画像であれば、⼊⼒画像を再現できるため、⼊⼒画像と出⼒画像の誤差は⼩さくなります。
⼀⽅、学習した画像と似ていない画像を⼊⼒した場合、⼊⼒画像をうまく再現することができず、⼊⼒画像と出⼒画像の誤差が⼤きくなります。
⼊⼒画像と出⼒画像の誤差が⼤きい場合、⼊⼒されたデータは正常ではない、つまり異常と判断することができます。
この仕組みによりオートエンコーダの学習には、収集が難しい異常データは必要なく、⽐較的収集が容易な正常なデータのみを学習させることで、異常検知を⾏うことができます。
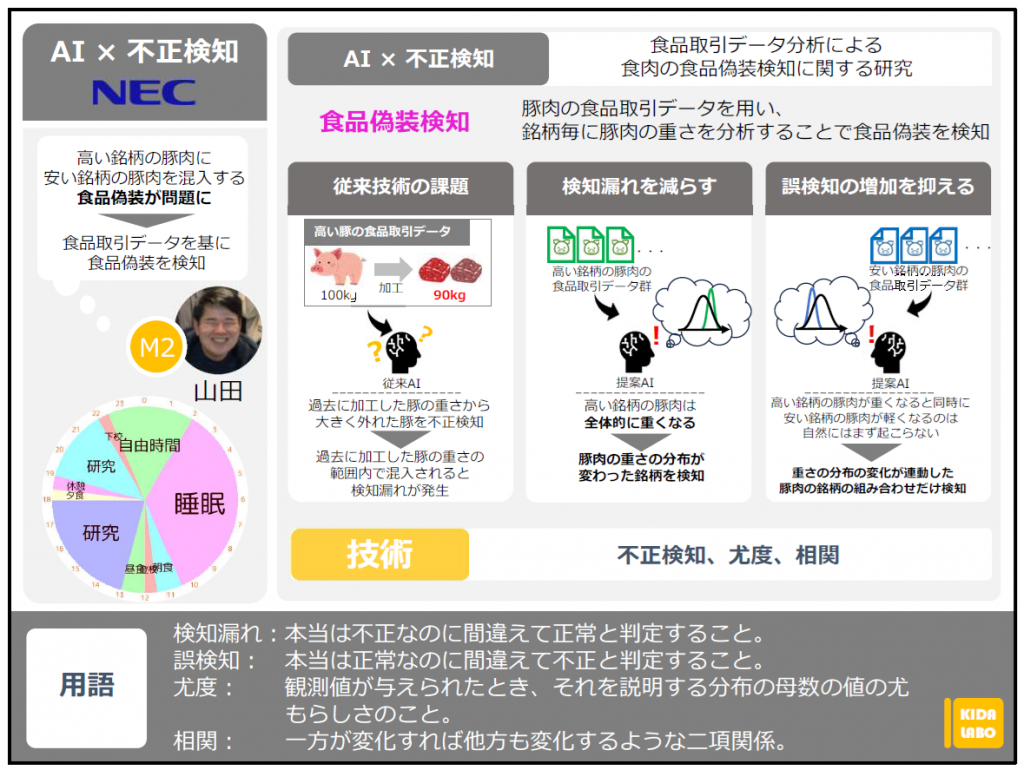
食品取引データ分析による 食肉の食品偽装検知に関する研究
【研究テーマ】
不正した事業者の検知に向け、豚肉の食品取引データを用いる不正検知方式の開発
【本研究で検知対象とする食品偽装】
高価な銘柄の豚肉に、海外産などの安価な銘柄の豚肉を混入する食品偽装
【従来技術の問題点】
従来技術では、過去に加工した豚の重さから大きく外れた豚を不正検知。
例えば、通常は100kgの豚を解体すると90kg前後の肉が得られる場合、99kgの肉が得られたと偽ると検知可能。
従来方式には、以下の二つの問題点がある。
問題点①:過去に加工した豚の重さの範囲内で混入されると検知漏れが発生。
具体例:100kgの豚を解体して85kgしか肉が得られなかった場合、5kg分混ぜて90kgに偽っても見つけられない。
問題点②:食品偽装とは無関係の要因により、特定の体重の豚から得られる肉の重さが全体的に増減した場合に誤検知が発生。
具体例:季節変動によって、加工に伴う廃棄ロスが増えて、得られる肉の重さが軽くなったときに誤って検知してしまう。
【問題点①の解決アイデア】
不正をする食品事業者は、より多くの利益を得るために、食品偽装を何度も繰り返し行うため、高価な銘柄の豚から得られる肉の重さが全体的に重くなるという現象が起きる。
そこで、肉の重さの分布を監視し、その分布が変わった銘柄を検知することで検知漏れを減らす。
【問題点②の解決アイデア】
食品偽装により、高価な銘柄の豚肉が全体的に重くなると同時に安価な銘柄の豚肉が全体的に軽くなるという、自然にはまず起こらない現象が起きる。
そこで、重さの分布の変化が連動した豚肉の銘柄の組み合わせだけ検知することで誤検知を減らす。
4. 作品データが面白い
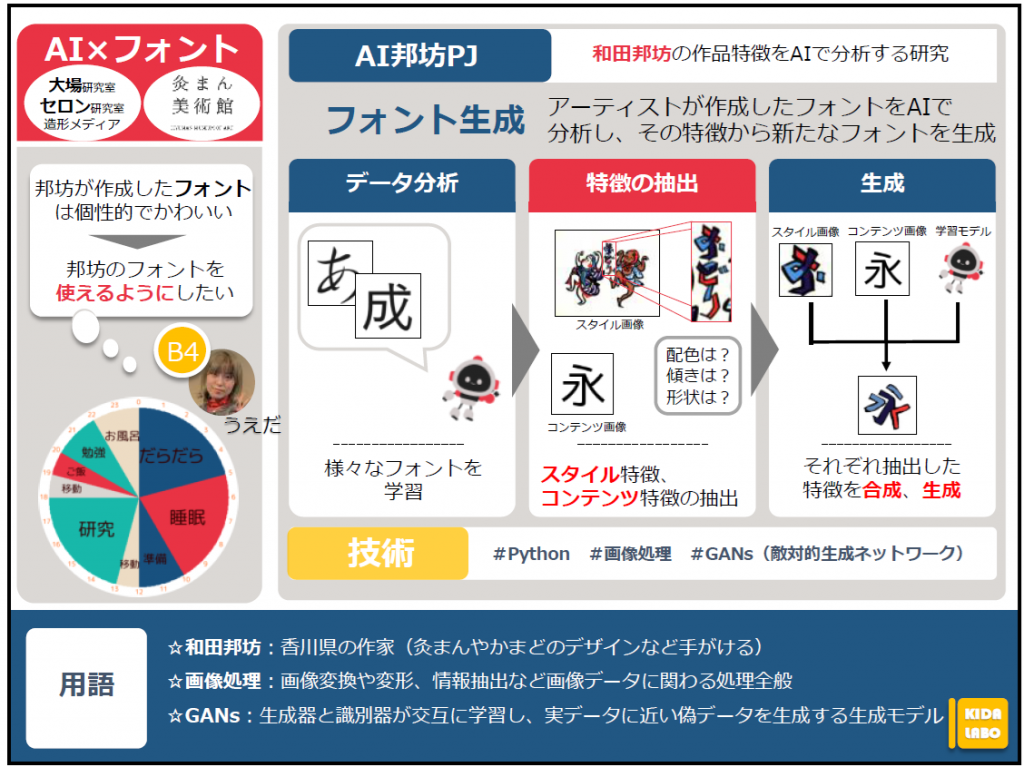
和田邦坊の作品特徴をAIで分析する研究
☆プロジェクトについて
香川県のアーティスト「和田邦坊」の絵画をAI分析し、新たな創作への支援をする研究をしています。
すでに亡くなっている邦坊の作品を、後世に残していくことが目的です。
造形・メディアデザインコースの大場研究室、セロン研究室と灸まん美術館と共同研究しています。
☆研究
GANsという生成モデルを用いて邦坊風フォントを生成する研究を行っています。
現在、色や傾き、質感など細かいスタイル情報を反映することができていないため、今後の課題です。
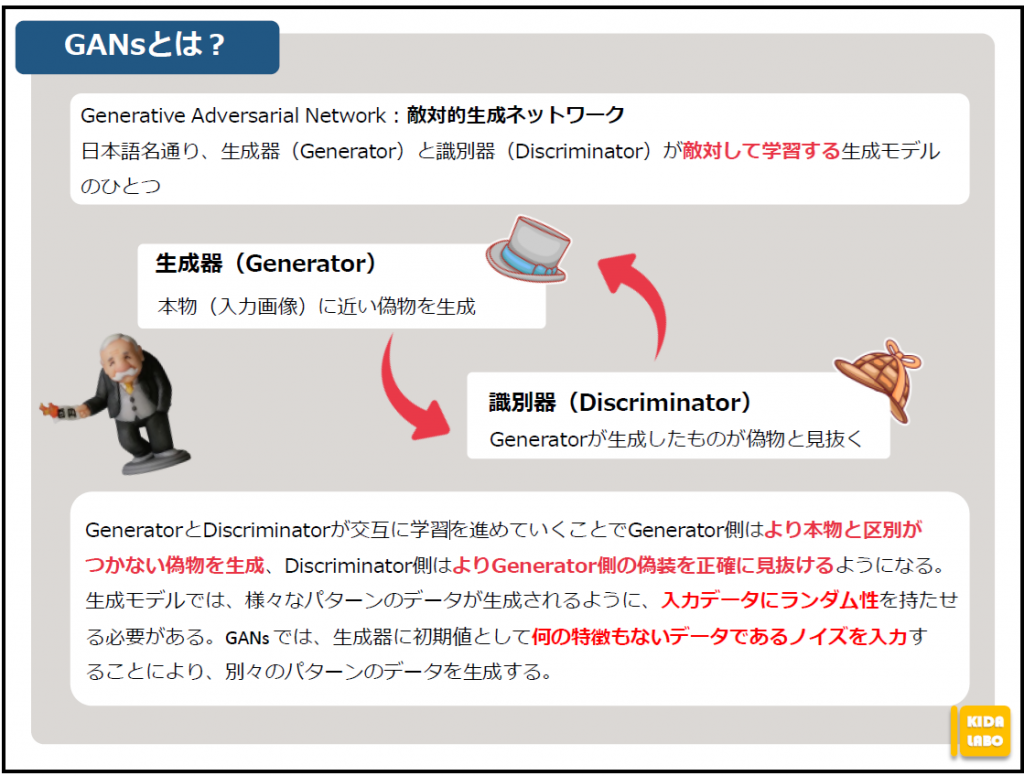
☆GANs
生成器と識別器が交互に学習し、実データに近い偽データを生成する生成モデルの1つです。
生成器はより本物(スタイル画像)に近い偽物を生成できるように学習し、識別器は生成器が生成した偽物をより正確に判別できるよう学習します。
交互に学習を行うことでお互いに切磋琢磨するように学習していき、より本物に近い画像を生成できるようになります。
GANs補足説明

バカリズムっぽい大喜利回答を生成するAIの開発
研究テーマ
私の研究では、バカリズムっぽい大喜利回答を生成するAIの開発を行っています。
背景
AI技術が進歩し、AIがクリエイティブなものを生成する時代が来ました。
中でも日本の”大喜利”に関する面白い研究やシステムがいくつか存在しています。
しかし、特定の人物に特化した大喜利AIつまり”誰かっぽい回答”ができるものはありません。
そこで本研究ではテキストの大喜利に焦点を当て、生成された回答をバカリズムの回答に近づけることを最終目標としています。
開発システム
・データ
本研究では主に2種類のデータを使用します。
①大喜利サイトから収集した大量のお題と回答データ
②ipponグランプリから収集したお題とバカリズムの回答データ
・LLM(ChatGPT)を調整
まずはRAGと呼ばれる検索技術を用いて①の中からお題に関連する回答、つまり大喜利回答を生成するための材料を集めます。
しかしRAGの強みは、最新かつ信頼性の高い情報を提供することにあり、独自の新しい回答生成には向いていません。
そこで登場するのがファインチューニングです。
②を基にLLMを微調整することでバカリズムっぽい独自の回答を生成できます。
「RAGが関連性の高い大喜利の回答を提供し、バカリズムっぽく学習されたLLMがそれを基に独自の回答を生成する」といった段階を踏んでLLMを調整することでバカリズムっぽいセンスを反映した回答を生成できるのです!!
5. インフラが面白い
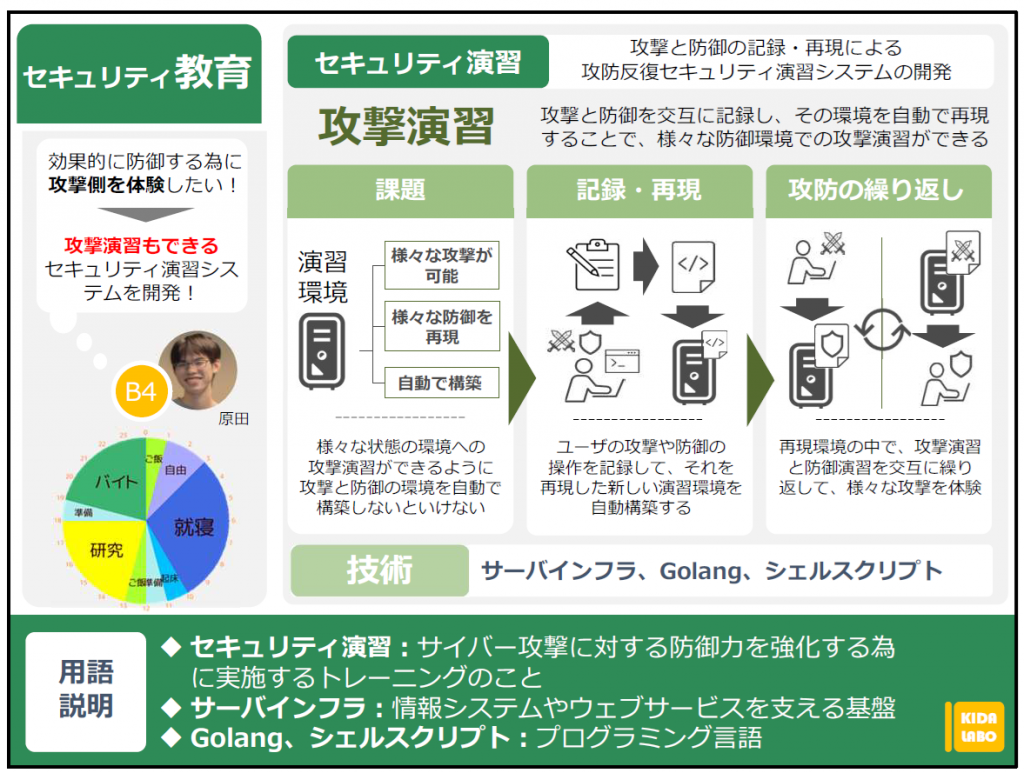
攻撃と防御の記録・再現による 攻防反復セキュリティ演習システムの開発
課題
受講者が一人で、サイバー攻撃の攻撃側と防御側の両方を学習できることを目標としています。
目標を達成できるセキュリティ演習環境を構築する上で、以下のようなことを解決できるようにします。
1. 様々な種類の攻撃手法が実践できること
2. 実践した攻撃に対する防御手法を実践できること
3. 演習環境の構築を受講者に負担をかけず行う事ができる
開発システム
私が開発するシステムは以下のような動作を行って課題を解決できるようにしています。
1. 受講者が行った攻撃や防御の操作を記録する。
2. 記録した操作を演習環境で実行可能なプログラムに作り替える。
3. そのプログラムが実行できる演習環境を自動で構築し、受講者が演習を開始するタイミングでプログラムが実行されるようにする。
これにより、利用イメージに合った演習を行うことで、課題が解決できると考えています。
利用イメージ
システムを起動すると攻撃が可能な無防備な状態の防御環境が構築されます。
以下の二つのモードを繰り返していくことで、攻撃と防御両方のセキュリティ演習を行う事ができます。
攻撃モード:前回のモードで行った防御の操作が再現された環境に対して、有効な攻撃を行う。
防御モード:前回のモードで行った攻撃の操作が再現される環境で、有効な防御を行う
この二つのモードを繰り返すためには、前回よりも高度な攻撃や防御を行っていく必要があるため、繰り返していく事で能力を向上させ続ける事が可能になると考えています。

サーバ管理演習における学習状況に合わせた ヒント提示に関する研究
研究テーマ
サーバ管理演習における学習状況に合わせたヒント提示に関する研究
背景
近年,サーバ管理技術を持つエンジニアの育成が急務となっており,特にサーバ管理演習による実践的な教育が行われている.
授業資料や演習内容が理解できず,問題への解答に行き詰まる受講者もいる.
その場合,受講者に対してTAがヒントを提示することで,行き詰まりを解消する.
しかし,受講者の数に対してTAの数が全然足りないため,受講者全員を支援することが難しい.
課題
闇雲にヒントを提示するだけでは既に解決した内容のヒントを提示したり,ヒントを与えすぎたりするという問題がある.
本研究では,行き詰まった受講者への支援を目指し,受講者の学習進捗状況に合わせたヒントを提示するシステムを開発する.
開発システム
受講者が行った操作を全部Pub/Subネットワークへ送信する.
受講者には自身の学習進捗状況に合わせたヒントのみが提示される.
これにより,既に解決した内容のヒントを提示したり,ヒントを与えすぎたりするという問題が解決される.
Pub/Sub
通信技術の一つ.
メッセージを送信する人とメッセージを受け取る人を分離することで,メッセージ送受信の構造をシンプルにした通信である.
一言でいうと,「宛先を設定しなくても通信を行える技術」.
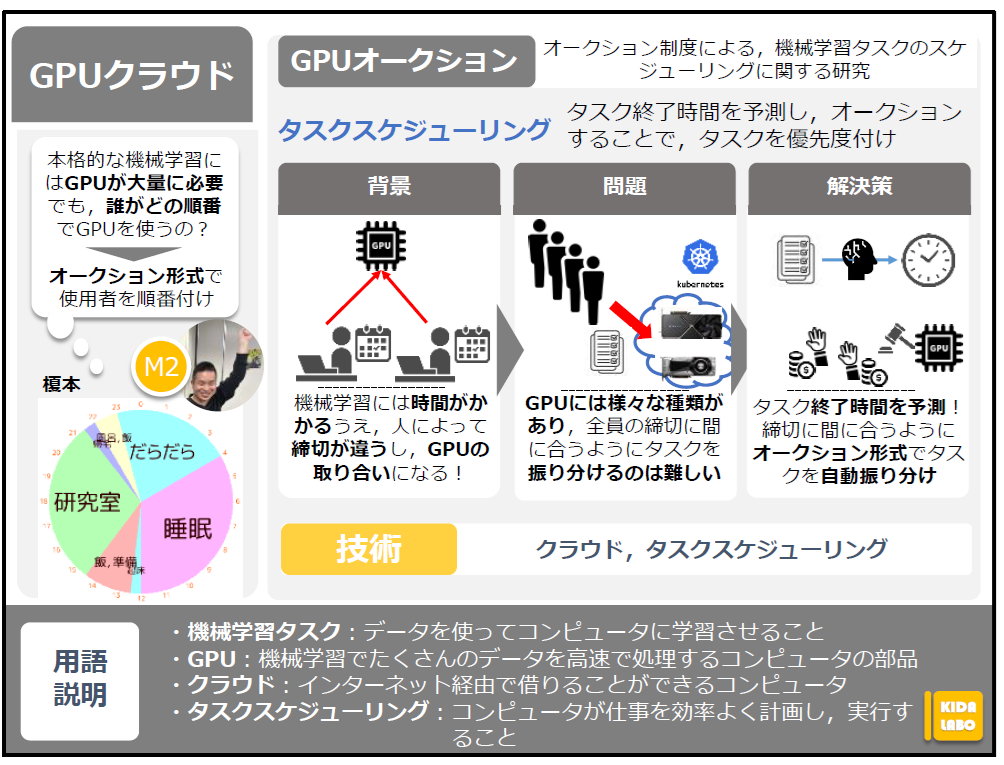
オークション制度による, 機械学習タスクのスケジューリングに関する研究
背景
近年,機械学習はとても注目されています.
大学でも様々な研究が活発に行われています.
しかし,機械学習は大量のデータをコンピュータが処理する必要があり,とても時間がかか
ります.
大量のデータを早く処理するためにはGPUというパーツが必要になります.
機械学習をする時は,待っている時間を短縮するために,たくさんのGPUが欲しくなります.
しかし,このGPUは数万から数十万するような,かなり高価なものになっています.
そのため,機械学習をしたい人とGPUの数が全く釣り合っておらず,GPUの取り合いが発生してしまいます.
問題
機械学習に使用するGPUには様々な種類があり,性能によって処理速度が大きく異なりま
す.
また,機械学習をする人には「この時間までには終わってほしい」といった締め切りがあります.
そのため,全員の締め切りに間に合うように,それぞれの機械学習を適切なGPUに振り分ける必要があります.
GPUの種類と全員の締め切りはバラバラであり,これはかなり難しいです.
解決策
この問題を解決するために,機械学習の終了時間を予測し,オークション形式でGPUの利
用権を割り当てるシステムを開発します.
まず,これから実行される機械学習の時間を予測します.
さらに,GPUの使用状況を常に監視します.これによって全員の機械学習の終了時間を求めます.
さらに,仮想的な貨幣を導入し,機械学習をする人が,その機械学習に割り当てる予算を
設定できるようにします.
つまり,誰がGPUを使うことができるのか,使用権を競り合うということになります.これによってそれぞれの機械学習の優先度を決定することができます.
この2つによって,全員の締め切りと優先度を考慮した,機械学習を自動で適切なGPUに振
り分けることができるシステムを開発します.
神戸親和大学 × 香川大 AIを用いた野菜判定アプリ ベジカメ




